
Retrieval-Augmented Generation (RAG) is a framework that enhances the performance of large language models (LLMs) by combining retrieval mechanisms with generative capabilities. It integrates the strengths of information retrieval systems and generative AI to provide accurate, contextually relevant responses, significantly reducing the likelihood of hallucinations.

How RAG Works
- Retrieval:When a user submits a query, a retrieval mechanism, such as vector similarity search or keyword-based search, is employed to fetch relevant documents or data from a knowledge base.This ensures the LLM has access to accurate, up-to-date, and domain-specific information, supplementing its training data.
- Generation:The LLM combines the information it retrieves with its understanding of language to create a clear and accurate response.
Basic Workflow:
Input query → Retrieve relevant data → Generate response using retrieved data.
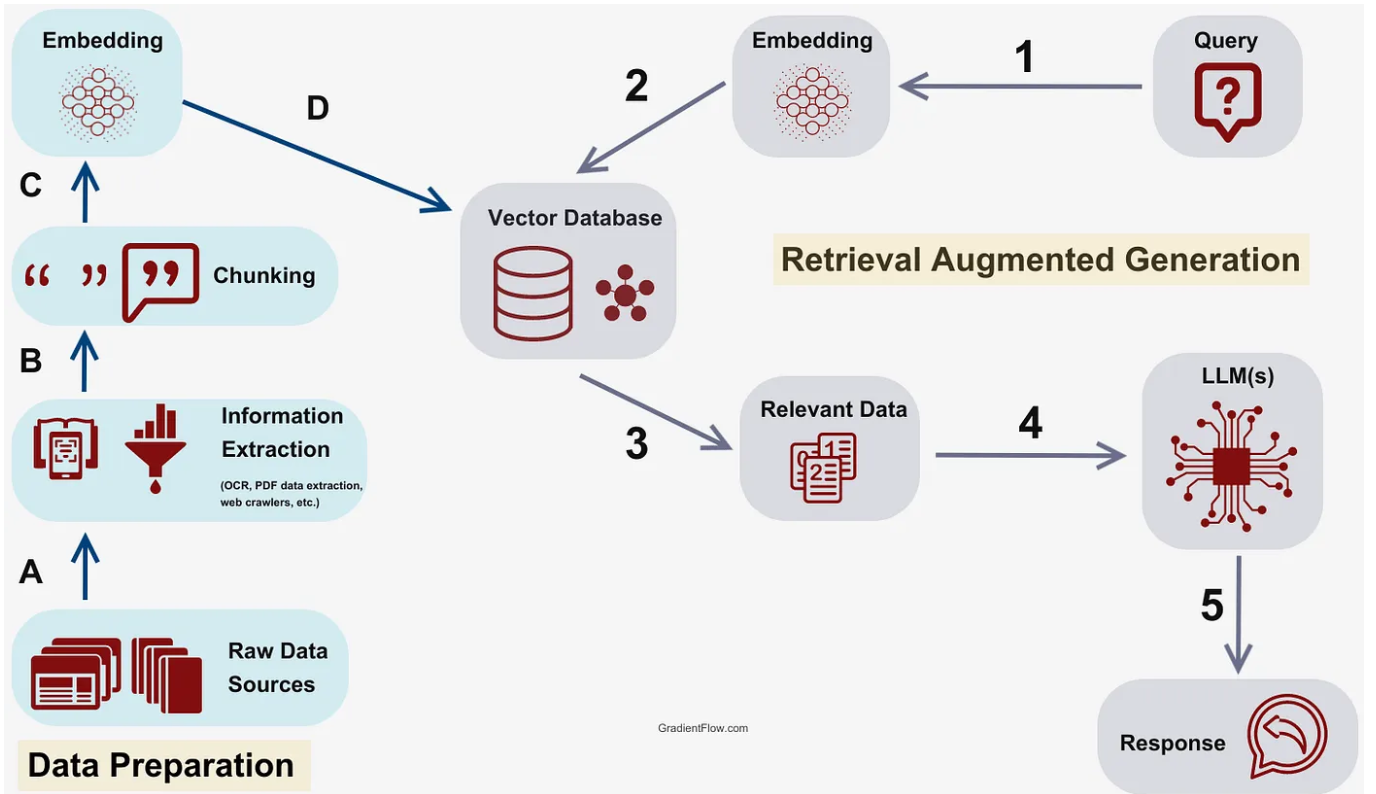
Source: https://gradientflow.com/techniques-challenges-and-future-of-augmented-language-models/
How RAG retrieves information and LLM generates responses based on user query
In a Retrieval-Augmented Generation (RAG) pipeline, the integration of retrieval and generation ensures that responses are grounded in external, relevant information.
1. Embedding Creation
- Document Embeddings:The documents in the knowledge base are preprocessed and converted into dense vector representations (embeddings).Models like Sentence Transformers or pre-trained BERT variants are commonly used for this step.These embeddings are stored in a vector database (e.g., Pinecone, FAISS,ChromaDb) for efficient similarity searches.
- Query Embeddings:When a user submits a query, the query is transformed into a similar dense embedding using the same or compatible model. This ensures that both document and query embeddings exist in the same vector space.
2. Retrieval Process
- Matching Embeddings:The query embedding is compared against all stored document embeddings using similarity metrics such as cosine similarity or Euclidean distance.The top k documents – those most similar to the query embedding – are retrieved for further processing.
3. Query and Context Preparation
- Query:The original user input remains as the “query” and represents the question or request that needs an answer.
- Context:The retrieved documents are processed to extract relevant information.This context serves as external knowledge that will help the LLM generate a grounded response.Techniques include:
- Trimming long documents to only include the most important parts.
- Summarizing or concatenating relevant snippets to form a coherent context.
4. Prompt Construction
The prompt is designed to give the LLM enough information to answer accurately while keeping the input concise to avoid exceeding token limits.The key components of the prompt passed to the LLM include:
- Query: The original user input.
- Context: The retrieved and preprocessed information, appended or integrated into the prompt.

5. Response Generation
- The LLM processes the prompt and generates a response based on the combination of:
- The context (grounded information).
- The query (specific question or task).
How RAG Mitigates Hallucination in LLMs
Hallucination occurs when an LLM generates outputs that are incorrect, fabricated, or not grounded in reality. This often arises due to limitations in the model’s training data or its inability to access external knowledge.
Example of Hallucination:
- Prompt: “What’s a good exercise for building muscles?”
- Hallucinated Response: “Try the ‘Chest Blaster 3000’ routine. It involves 300 reps of dumbbell flyes in a single set. It’s guaranteed to give you massive gains in just one week!”
- Reason: The model may have encountered limited or extreme data points during training and extrapolated incorrectly, producing an unrealistic and potentially harmful recommendation.
RAG’s Solutions to Hallucination:
1. Grounding Responses in External Data:
- RAG retrieves real-world information, grounding responses in factual data. This reduces reliance on the model’s internal (and potentially outdated) knowledge.
2. Dynamic Knowledge Updates:
- RAG allows for real-time integration of updated information, which is critical for fast-changing domains like healthcare, technology, or news.
3. Improved Transparency:
- Retrieved documents or evidence can be shown alongside the response, enabling users to verify the accuracy and trustworthiness of the output.
4. Domain Adaptation:
- By focusing retrieval on domain-specific databases, RAG ensures contextually accurate and specialized responses (e.g., a legal chatbot retrieving information from legal documents).
- Relevant contextual data reduces the likelihood of the generative component making incorrect assumptions or fabricating details.
- Prompt: “What’s a good exercise for building muscles?”
- RAG-Enhanced Response: “To build muscles, try compound exercises like squats, deadlifts, bench presses, and pull-ups. Aim for 8–12 reps per set with challenging weights, and progressively increase resistance over time. Maintaining proper form is crucial to avoid injuries.”
- Reason: The system retrieves verified advice from a fitness database, ensuring the response is both realistic and helpful.
Practical Applications of RAG
- Customer Support:
– Retrieve information from knowledge bases to deliver accurate solutions to user queries.
-
Research Assistance:
– Retrieve scientific papers or technical documents to support research inquiries.
-
Education:
– Provide fact-based explanations using reliable educational resources.
-
Healthcare:
– Offer accurate medical advice by referencing validated guidelines and literature.
By integrating retrieval capabilities, RAG empowers LLMs to act as knowledgeable and reliable assistants. This approach addresses hallucination effectively, enabling LLMs to deliver trustworthy and practical solutions in various domains.