
In the previous part we finished building an API to fetch all news items from a database. In this part we will build a scraper that will extract the link, title and image URL from news portals.
We are going to be scraping the title, link and related image of news articles from these news portals:
https://www.setopati.com/
https://ekantipur.com/
For this purpose we will be using Scrapy. You can learn more about scrapy at: https://scrapy.org/
To install scrapy, run this command in your terminal:
pip install scrapy
After the installation is done, create a new directory called scraper inside the root directory (news-aggregator). Switch to scraper directory from the terminal:
cd scraper
Then start the project:
scrapy startproject newscraper
The period . at the end installs the code in our current directory scraper.
This will create a directory called newscraper and a file called scrapy.cfg inside the folder scraper.
Before writing the scraping logic, we will configure our crawler first. Open settings.py which is inside the folder newscraper. It contains settings for the crawlers. If you look at around line 20 you will see:
news-aggregator/scraper/newscraper/settings.py
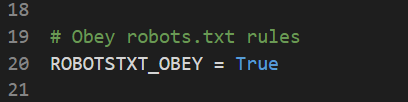
This settings tells the crawler whether to obey the robots.txt of the website it is crawling. If you go to https://www.setopati.com/robots.txt, you will get something like this:

The robots.txt contains instructions intended for web crawlers. If a crawler has ROBOTSTXT_OBEY set to True, it will not open the pages that have been disallowed in the robots.txt. The robots.txt of setopati.com doesn’t allow crawlers to access the page https://www.setopati.com/login/ and any page containing /login. For example, the crawler cannot crawl the page https://www.setopati.com/login/user1.
A Scrapy spider always opens the robots.txt file first before starting the scraping process.
Obeying robots.txt is optional, but for this project we are going to leave it to True.
Below the ROBOTSTXT_OBEY, you will find the settings for concurrent requests:
news-aggregator/scraper/newscraper/settings.py

This setting specifies the maximum number of concurrent (simultaneous) requests Scrapy can make. In this case, it is commented out, meaning the default value of 16 is used. If you explicitly set CONCURRENT_REQUESTS to, for example: 8, Scrapy will process up to 8 requests simultaneously.
Increasing this value can speed up the crawling process, as more requests are sent in parallel. However, sending too many requests in a short period of time may get you banned from scraping the target site. Some servers, especially those of smaller organizations, may have limited resources, and aggressive crawling can increase their server costs.
For personal projects, it’s a good practice to keep this value as low as possible to minimize the impact on the websites you are scraping. Ethical scraping is not just about avoiding bans; it’s also about respecting the resources of others, especially smaller companies with limited server capacities.
So, let’s keep the concurrent requests to 1.
Uncomment the line and set concurrent requests to 1:
news-aggregator/scraper/newscraper/settings.py

Now we will generate spiders. Spiders are where we write the core logic for scraping or crawling. We can generate a boilerplate for spiders by running the command: scrapy genspider setopati www.setopati.com in the terminal. Ensure that your terminal’s current directory is the one containing the scrapy.cfg file before running the command. You can check this by running the command: ls in your terminal if you are using VsCode. If you are in the same directory as the scrapy.cfg file is located, the file will be listed.
The command: scrapy genspider setopati www.setopati.com generates a spider named setopati, which will crawl the domain setopati.com.
After the command finishes processing, if you look inside the spiders directory, you should see that a file named setopati.py has been created.
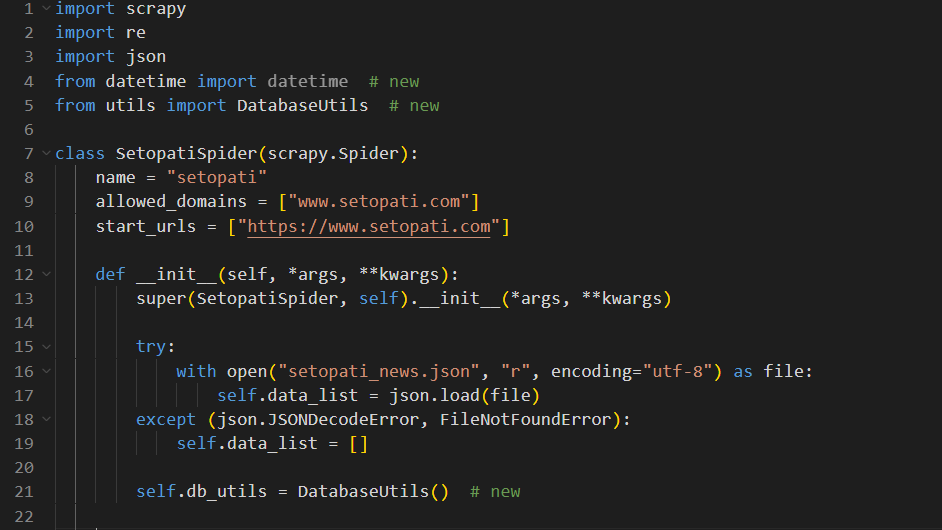
Open the file setopati.py, and you can see a class named SetopatiSpider.
news-aggregator/scraper/newscraper/spiders/setopati.py
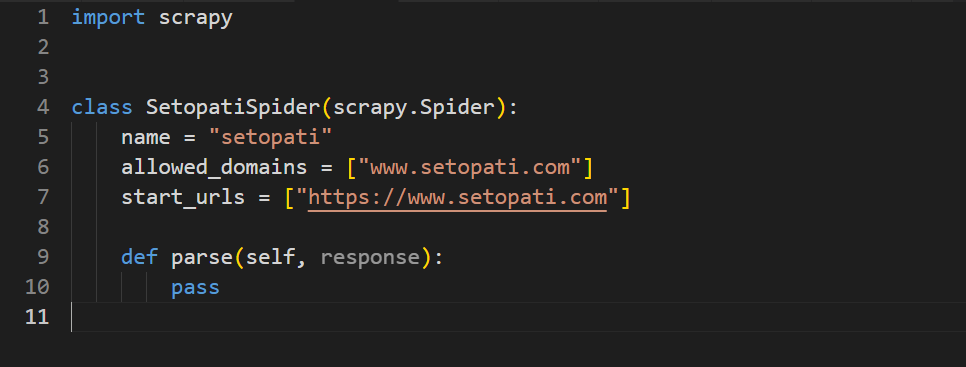
It has the attributes: name, allowed_domains and start_urls, along with a method called parse.
The name attribute specifies the name of the spider, allowed_domains specifies the list of domains that this specific spider is allowed to crawl. In our case it is www.setopati.com, so our spider will not open any link that doesn’t have www.setopati.com as its domain.
The start_urls attribute contains a list of URLs that the crawler will begin crawling from. In this case, it includes the URL https://www.setopati.com, meaning the spider will open and start processing this link when it begins.
If you add additional URLs to the list, such as: https://www.setopati.com/politics, the crawler will sequentially process each URL in the order they are listed. For example, it will first crawl https://www.setopati.com/ and then move on to https://www.setopati.com/politics.
Approach to Scraping News Items from Setopati Website
We will be processing all the news from the homepage of https://www.setopati.com/ .
If you open the website, right click on the first news, and click Inspect, the browser’s DevTools opens up:
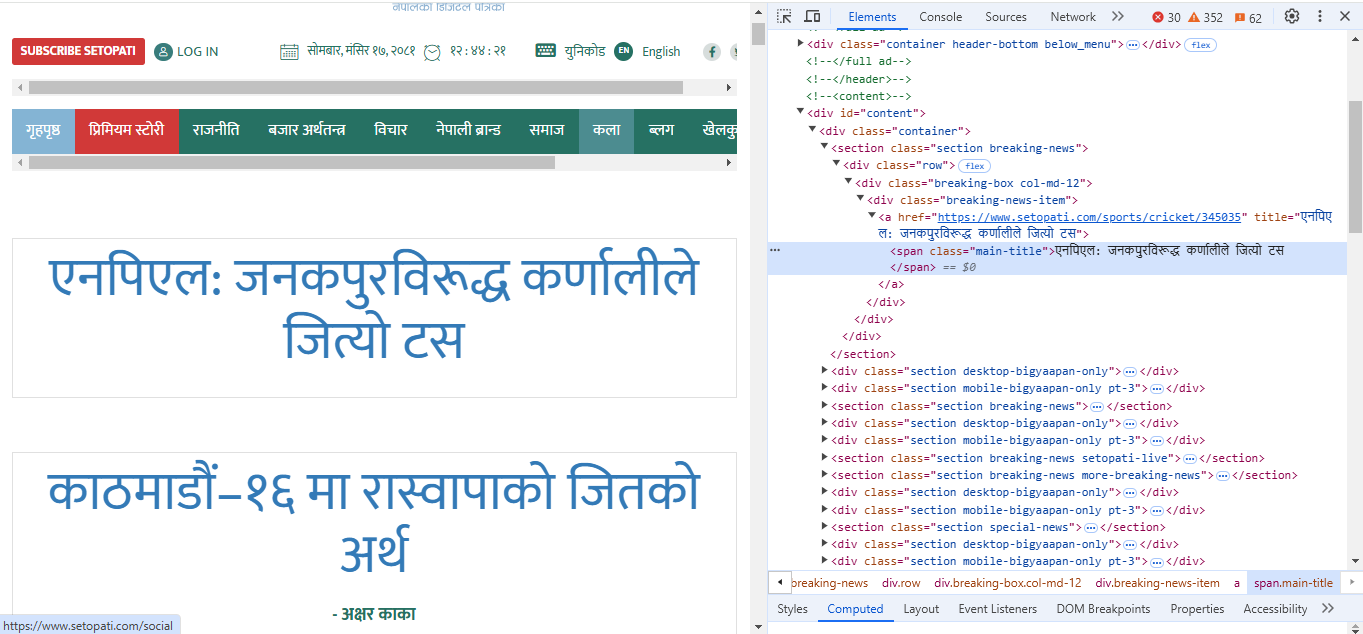
Here, the title of the news is inside the tag. If you look above the span tag, there is an “a” tag, which has the attribute href. Copy the value of the href attribute and open it. This will take you to the actual article link.
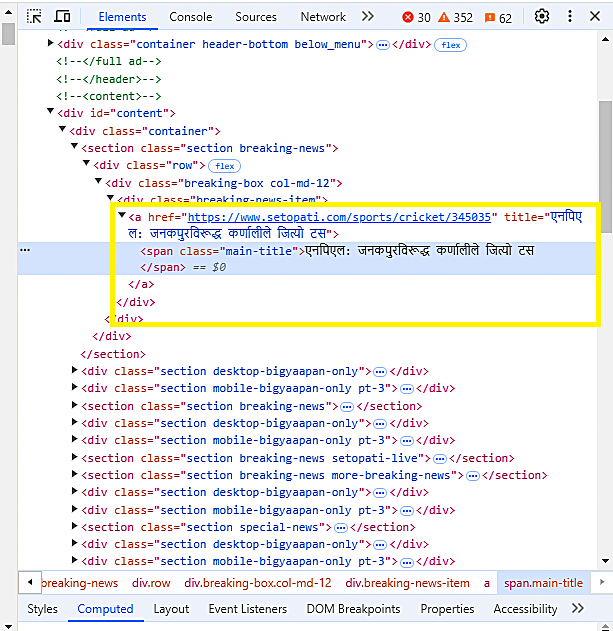
Upon inspecting more links on the home page we can observe that each news article has an “a” tag whose href attribute contains the link to the news article.
Here are some links that I extracted manually from random position on the page:
https://www.setopati.com/social/344063
https://www.setopati.com/exclusive/340187
https://www.setopati.com/sports/football/344065
If we analyse the links we can see a pattern forming:
https://www.setopati.com followed by social or exclusive or sports, etc. and then the rest of the URL.
We can create a regular expression to extract this type of url:
r"https://www\.setopati\.com/(social|exclusive|sports)/\.*"
This will match any link starting with https://www.setopati.com followed by social or exclusive or sports followed by anything.
Upon thoroughly inspecting the website, I created a pattern that will match the link of every category the site offers. You can add more to this if any category is added to the website.
r"https://www\.setopati\.com/(exclusive|banking|politics|social|kinmel|sports|nepali-brand|art|global|ghumphir|opinion|blog|cover-story)/\.*"
So, we will extract all the links that match the above pattern from the home page and then follow those links. From there we will extract the title and image URL of each news article.
Parsing the Home Page of Setopati
Let’s write our parse method to extract and follow all links available in the home page.
news-aggregator/scraper/newscraper/spiders/setopati.py
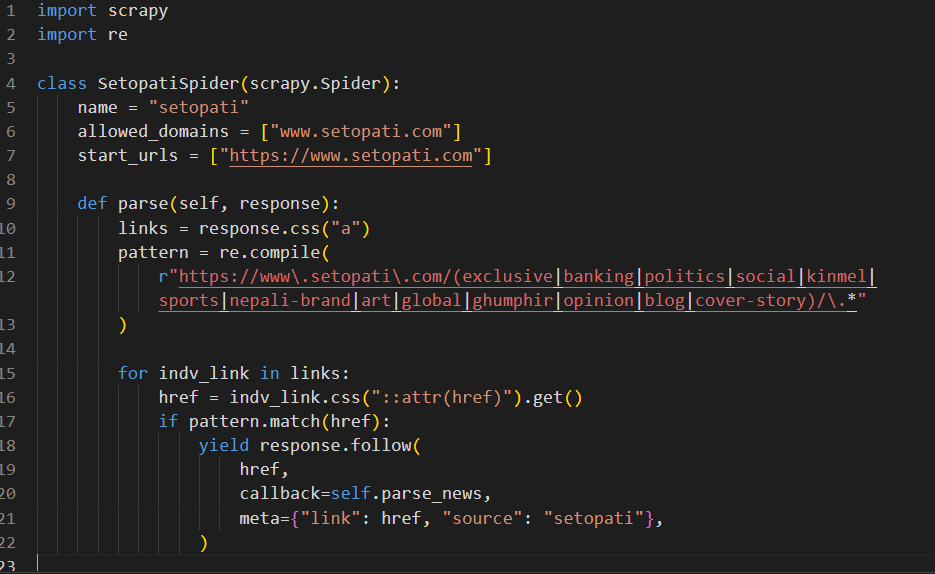
The parse method will grab all the “a” tags from the site https://www.setopati.com, and for each “a” tag found, it will extract the href attribute of the tag. Then it will check the href against the pattern defined above. If the href matches the pattern, it will be followed i.e, Scrapy will open the href. We have specified the callback as self.parse_news. This will make the code move on to the parse_news method. We will create the parse_news method shortly. We are also passing the actual link to the news article and its source to the parse_news method using the meta parameter. The variables included in meta can be accessed directly within the callback method (parse_news).
After opening the link to the article we will extract the title and the related image of the news article. For that, we will define the parse_news method and write our extraction logic there.
Parsing the News Article Page
If you open any news article you will get a page like this:
We will just need the title and the link of the main image from this page. Inspect the page in the DevTools: right click on the title of the news article, and then click Inspect.
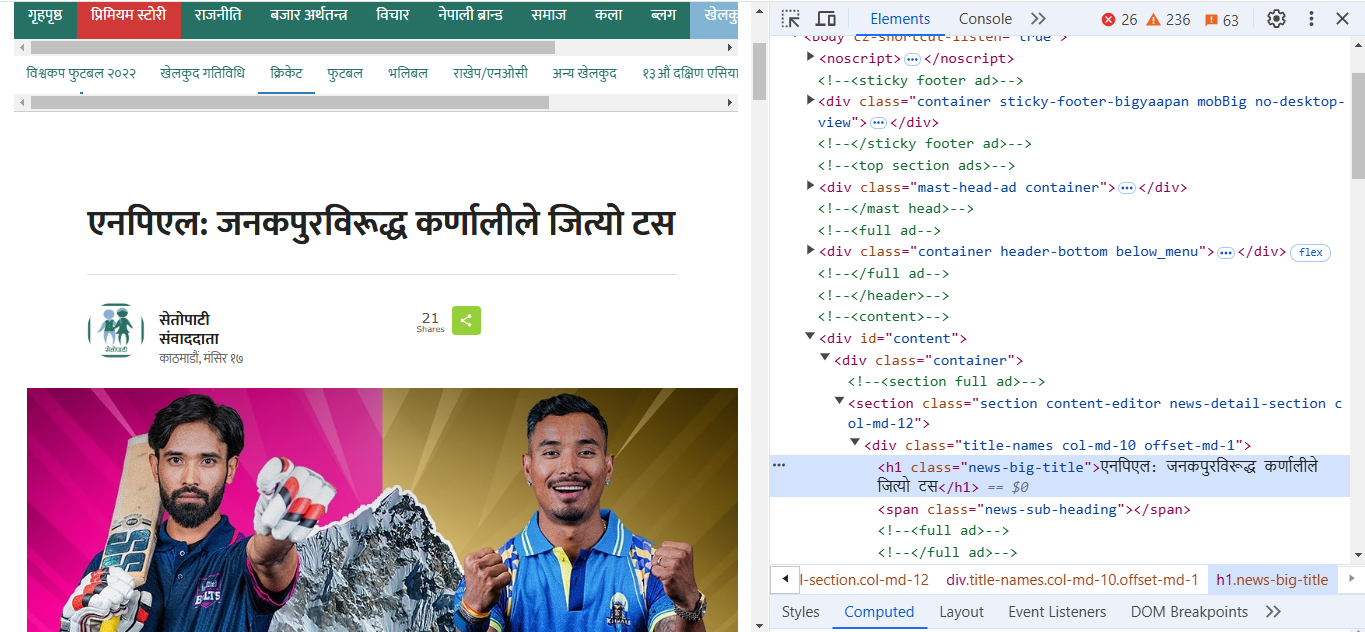
Here, you can see that the headline of the news is inside a
“h1” tag with a class “news-big-title”. So we will find a “p”
“h1” tag with the class “news-big-title” and extract its text.
For the image link, if we inspect the image we can see that the image link is inside an “img” tag, which itself is inside a “p”
“figure” tag and the “p”
“figure” tag is inside a “p”
“div” tag with the class “featured-images col-md-12”. The href attribute of the “img” tag holds the link to the image.
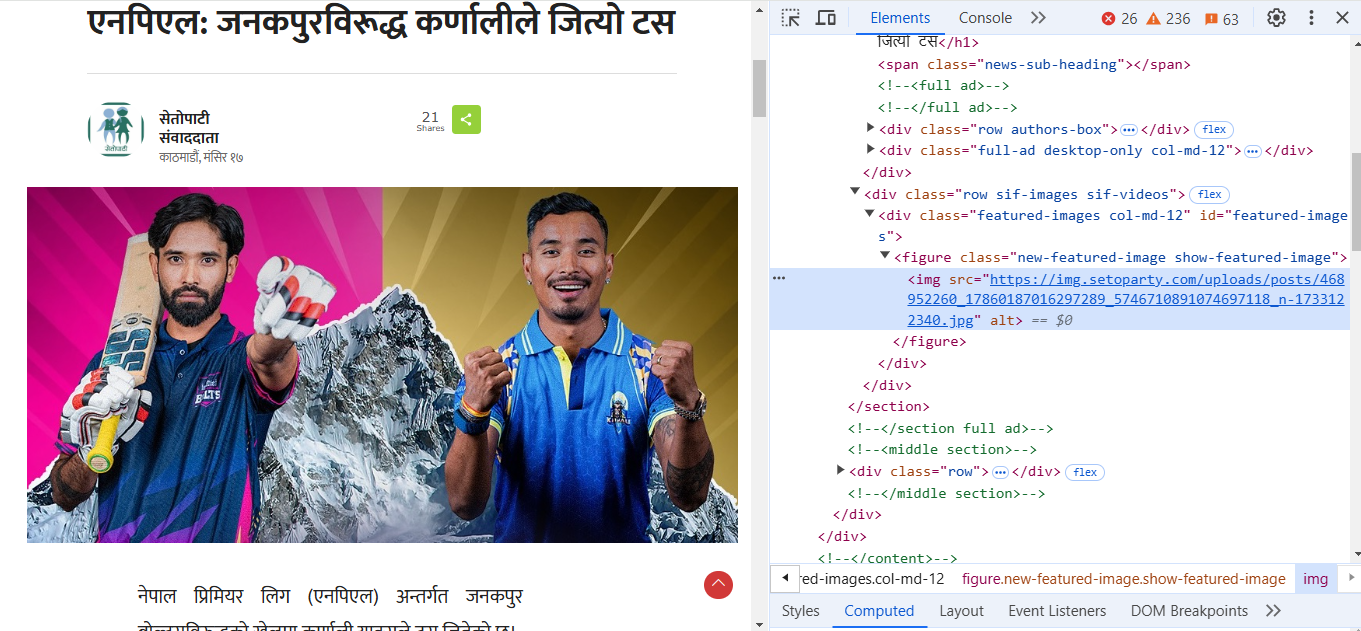
So we will write our parsing logic accordingly.
news-aggregator/scraper/newscraper/spiders/setopati.py
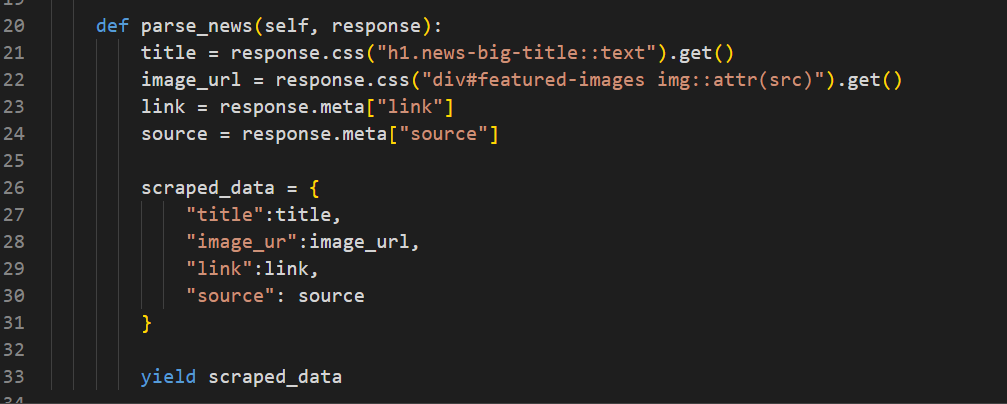
Within the parse_news method, we locate the news title by targeting the
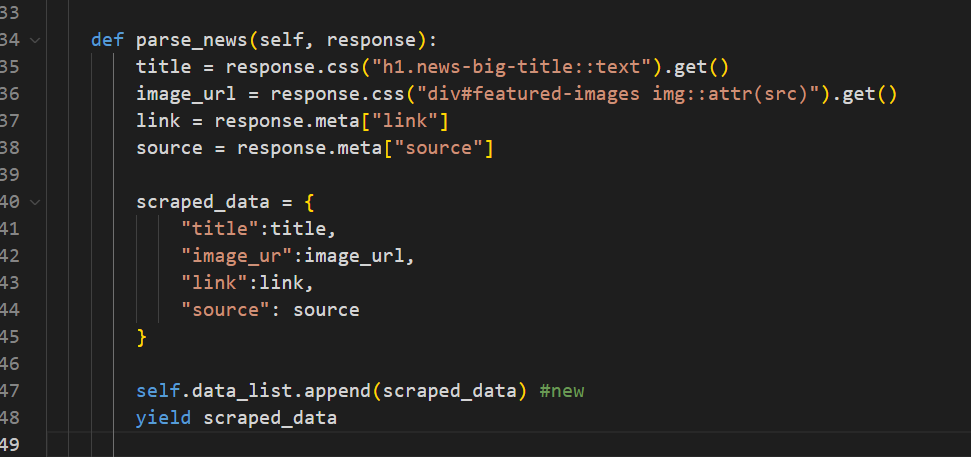
“h1” tag with the specified class name. We then extract its text using ::text . Finally, we call get() to ensure that only the first result is returned as a single value, rather than a list. Similarly, we get the image link by finding the required element using the specified class name. After that, we get the link of the news article and source from the meta. Remember, we passed link and source using meta from the parse method. Then we store the extracted data in the variable scraped_data and yield it.
You can test the crawler using the command: scrapy crawl setopati -O setopati_news.json
Ensure that your terminal’s current directory is the one containing the scrapy.cfg file before running the command.
This should run the crawler, and after it finishes a setopati_news.json will be created. Inspect the JSON file and make sure it has a list of news objects containing title, image_url, link and source.
Since we will be running multiple spiders, 2 in our case, we should create a mechanism to run both crawlers from a single command. For that, we will create a main.py file which when run will start both crawlers.
Create a file, main.py in the same directory in which the scrapy.cfg file is located. Then add the following:
news-aggregator/scraper/main.py
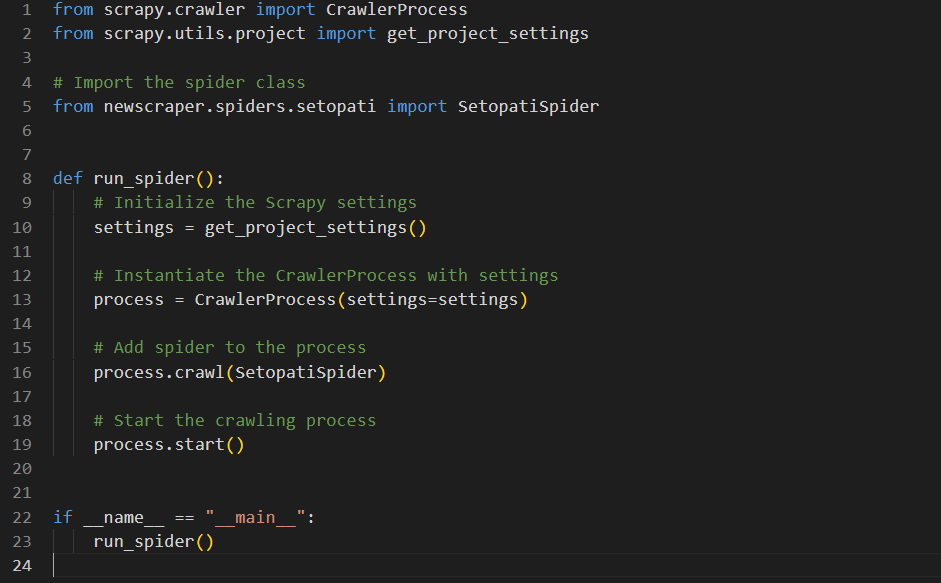
Here we imported the SetopatiSpider along with other necessary imports. Then we defined a function run_spider which will start the spider when called.
Now if you run: python main.py in your terminal, it should start the SetopatiSpider.
But we have a small problem, although the spider runs and extracts the data, it doesn’t store the data in a JSON file. This is because previously we used the command: scrapy crawl scrapy crawl setopati -O setopati_news.json explicitly instructed scrapy to write the scraped data in the setopati_news.json file. But now we are running the spider using the command: python main.py. So we will have to write the logic to store the data in a JSON file as well. The reason for storing the data in a JSON file is to speed up duplicate filtering. Instead of querying the database each time to check if a news article already exists in our database, we will store all the news in a JSON file and check if the news already exists in the file. If the news exists we won’t process that news. This will reduce the performance overhead.
For filtering duplicates, we will read the file called setopati.json. If the file exists, we will load the data from it. Then, we will check if the URL of a news article already exists in our JSON file before processing it. If the URL exists in our JSON file, we will skip processing it, else we will go ahead and process it.
news-aggregator/scraper/newscraper/spiders/setopati.py
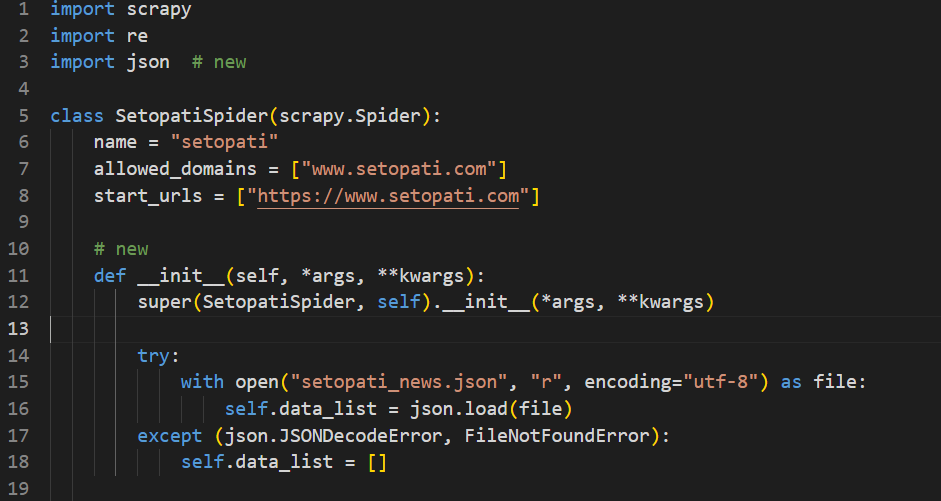
Here, we try to read the file called setopati_news.json when the crawler starts. If the file exists, we load the data from it to data_list, else we keep the data_list as an empty list.
Now we will add the duplicate filtering logic inside the parse method.
news-aggregator/scraper/newscraper/spiders/setopati.py
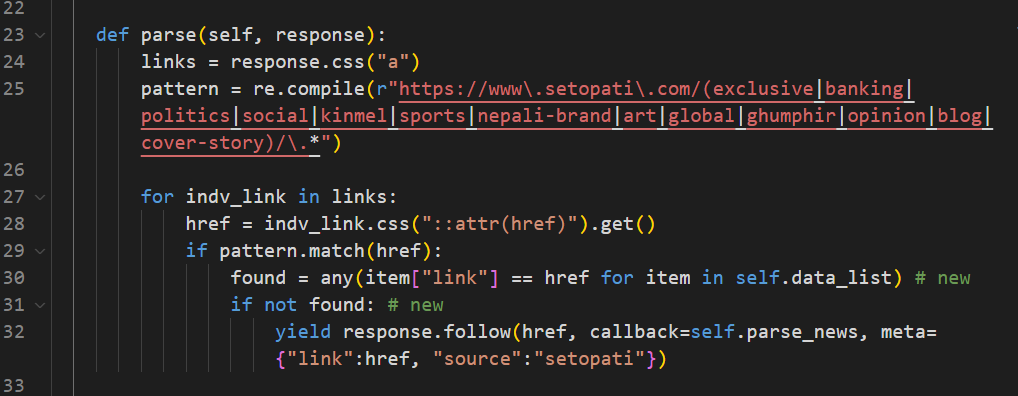
The parse function will now loop through the “a” tags in the home page, extract the link from the href attribute inside the tag, compare the link against the pattern defined, then it will check if the link already exists in our JSON file. If the link exists in our JSON file, found will be True, else it will be False. The link will be followed and parsed only if found is False.
Now after extracting the title and image from a news article, it should be added to data_list, in order to update it.
news-aggregator/scraper/newscraper/spiders/setopati.py
Finally, we will define a method called closed at the bottom, which will write the collected data in a JSON file.
news-aggregator/scraper/newscraper/spiders/setopati.py

This will write the collected data in a JSON file after the spider finishes crawling.
Delete the JSON file setopati_news.json if it exists, then run the crawler using the command: python main.py in the terminal.
After the crawler finishes data extraction, a file called setopati_news.json should be created.
If you re-run the crawler, you will notice that it will stop earlier. This is because the links that are already in the JSON file will not be opened again.
Now we will store the collected data in the database. Install psycopg2 if you have not already: pip install psycopg2
We will create a separate class to handle database operations. First we will store database configuration in a separate file. Create a file config.py in the directory where scrapy.cfg is located. Then inside the file add:
news-aggregator/scraper/config.py
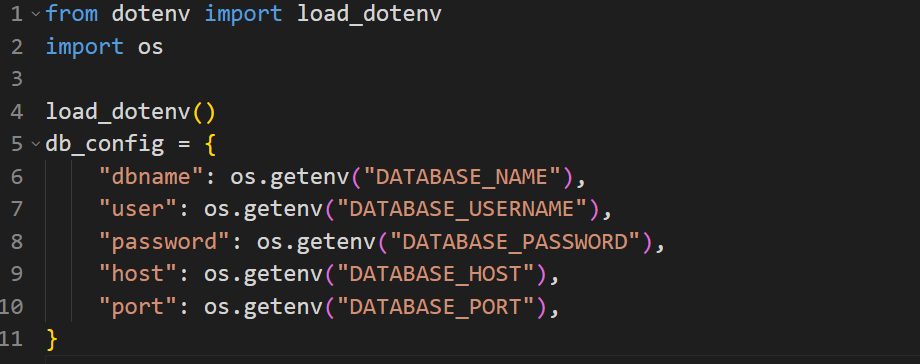
Here we import os and load_dotenv. Then we initialize load_dotenv. After that, we store the database configuration in the db_config dictionary.
Make sure you have already created a .env file, see part – 1 of this blog.
Now create utils.py in the same directory.
Inside it, write a DatabaseUtils class that has methods to connect to the database, insert data into the database, and close the connection.
news-aggregator\scraper\utils.py
import logging
import psycopg2
from psycopg2 import sql
from config import db_config
from datetime import datetime
class DatabaseUtils:
def __init__(self):
self.connect_to_db()
def connect_to_db(self):
"""Establishes a connection to the database and creates a cursor."""
try:
self.connection = psycopg2.connect(**db_config)
self.cursor = self.connection.cursor()
logging.info("Database connection successful")
except Exception as e:
logging.exception(f"Error connecting to database: {str(e)}")
self.connection = None
self.cursor = None
def insert_data(self, table_name, data):
if not self.cursor:
logging.error("No database connection. Insert failed.")
return
# Convert datetime fields to strings
for key, value in data.items():
if isinstance(value, datetime):
data[key] = value.isoformat()
columns = data.keys()
values = data.values()
insert_query = sql.SQL(
"""
INSERT INTO {table} ({fields})
VALUES ({placeholders})
"""
).format(
table=sql.Identifier(table_name),
fields=sql.SQL(", ").join(map(sql.Identifier, columns)),
placeholders=sql.SQL(", ").join(sql.Placeholder() * len(columns)),
)
try:
self.cursor.execute(insert_query, tuple(values))
self.connection.commit()
logging.info(f"Data inserted successfully into {table_name}")
except psycopg2.Error as e:
logging.exception(f"Error inserting data: {str(e)}")
self.connection.rollback()
def close_connection(self):
if self.cursor:
self.cursor.close()
if self.connection:
self.connection.close()
logging.info("Database connection closed")
Here, after performing necessary imports, we define a class DatabaseUtils. When an instance of the class is initialized, it immediately establishes a connection to the database by calling the connect_to_db method. This method attempts to connect using the database configuration provided and initializes a cursor for executing SQL queries.
The insert_data method allows inserting records into a specified table. It takes two arguments: the name of the target table (table_name) and the data to be inserted (data), which is expected to be a dictionary. Before insertion, it processes the data by converting any datetime values into ISO 8601 formatted strings.
The keys of the data dictionary will be columns and values will be rows. Then we use raw SQL to insert data into the database. Finally, the method close_connection closes the database connection.
Now we will use this class in our spider. Open the spider file setopati.py. Import datetime and DatabaseUtils, then initialise DatabaseUtils.
news-aggregator/scraper/newscraper/spiders/setopati.py
After that, inside the parse_news method, use the insert_data method to store the data in our database.
news-aggregator/scraper/newscraper/spiders/setopati.py
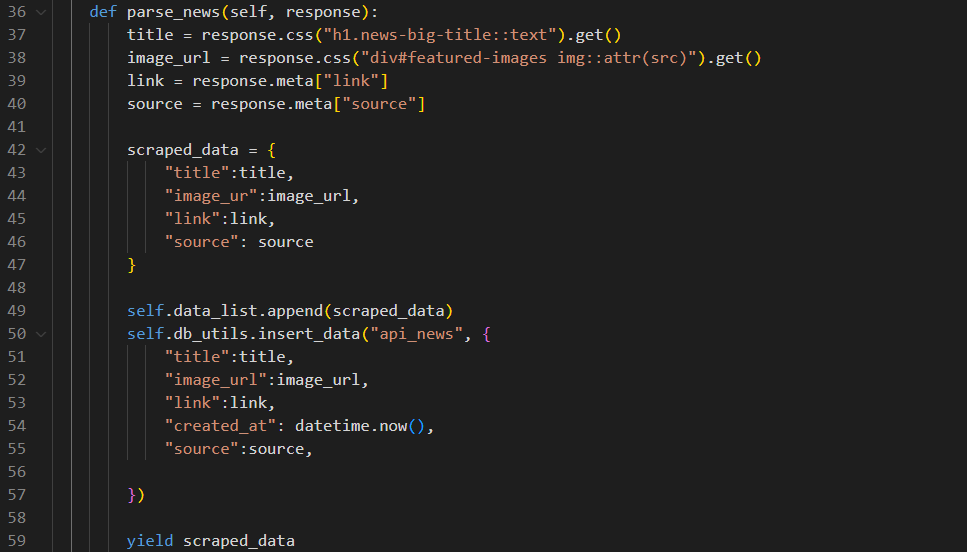
Here we pass the name of the table to store news items and the actual data with an additional field created_at, to the insert_data method after appending it to data_list.
We have already created the table api_news to store news items in the first part of this blog.
Finally close the database connection when the spider closes.
news-aggregator/scraper/newscraper/spiders/setopati.py
To test our progress up to now, run the crawler: python main.py after deleting the setopati_news.json file. The reason for deleting the JSON file is that the crawler will not store any data in this run because most of the data is already in the JSON file.
Then start the Django server in another terminal:
You can open multiple terminals at once by clicking on the plus icon on the top left of the current terminal in VsCode.
Navigate to the root directory in you terminal (where manage.py is located) and run: python manage.py runsever
Open the Django admin panel, go to: http://127.0.0.1/admin click on “News Items”. You should see the news items listed there. Verify that Title, Link, Source and Image URL are as expected.
We have successfully scraped news from https://www.setopati.com/ and stored it in our database.
Scraping Ekantipur
For scraping Ekantipur, we will use the API endpoint exposed at https://ekantipur.com/.
First go to https://ekantipur.com/, click on a category, for example: Sports (खेलकुद) and open developer tools (Control + Shift + I in Google Chrome).
Switch to the Networks tab and then click on Fetch/XHR.
Scroll down the website while keeping the developer tools open.
After you scroll sometimes you will get an API endpoint ending with ?json=true.
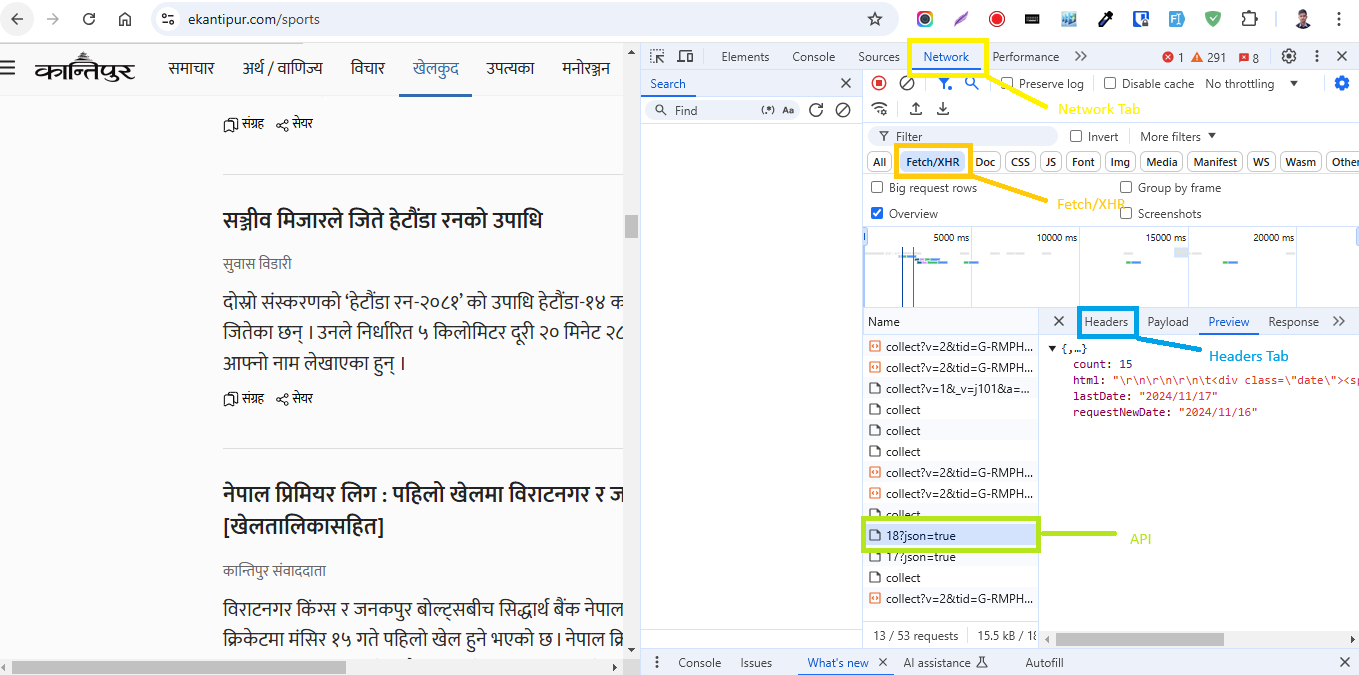
Switch to the Headers tab to get the API header. You should get something like this:
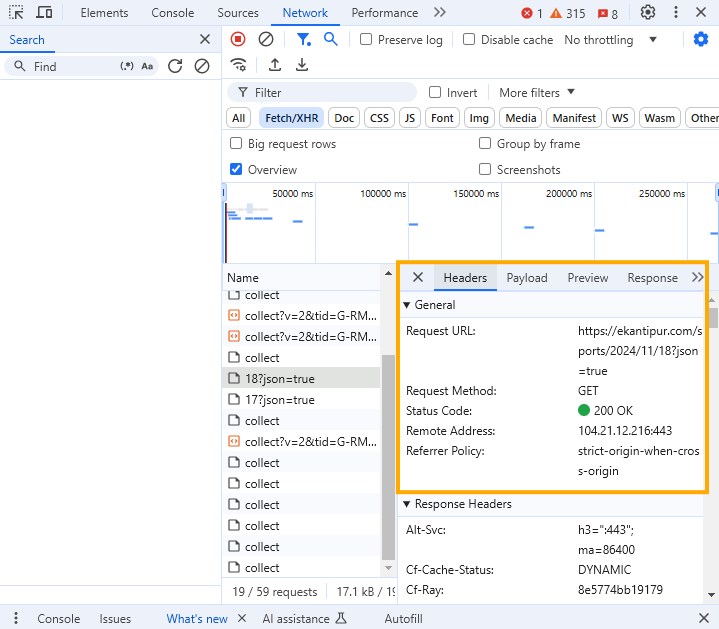
Copy the Request URL and try it out in Postman or Thunder Client (extension for VsCode).
You can get Postman here: https://www.postman.com/downloads/
In my case the URL is: https://ekantipur.com/sports/2024/11/18?json=true
If you try out the request in Postman the response will be like this:
{"html":"\r\n\r\n\r\n\tमंसिर ३, \u0968\u0966\u096e\u0967<\/span><\/div>\r\n\r\n\r\n\t

