
You may have come across Google News (https://news.google.com/) and wondered how it works. The basic principle behind the site is that Google crawls the sites they have listed as news sites and grabs the title, link and thumbnail of various news on the sites. Then they project the data they have gathered on their site.
In this blog we will go through building a similar application for gathering data, storing it and projecting it on our web application. We will be using Django with the Django REST framework, PostgreSQL, Scrapy and React for building our application.
By the end of this blog, you’ll have a full-stack application capable of fetching news from various websites, storing and managing it, and displaying it to users in real time.
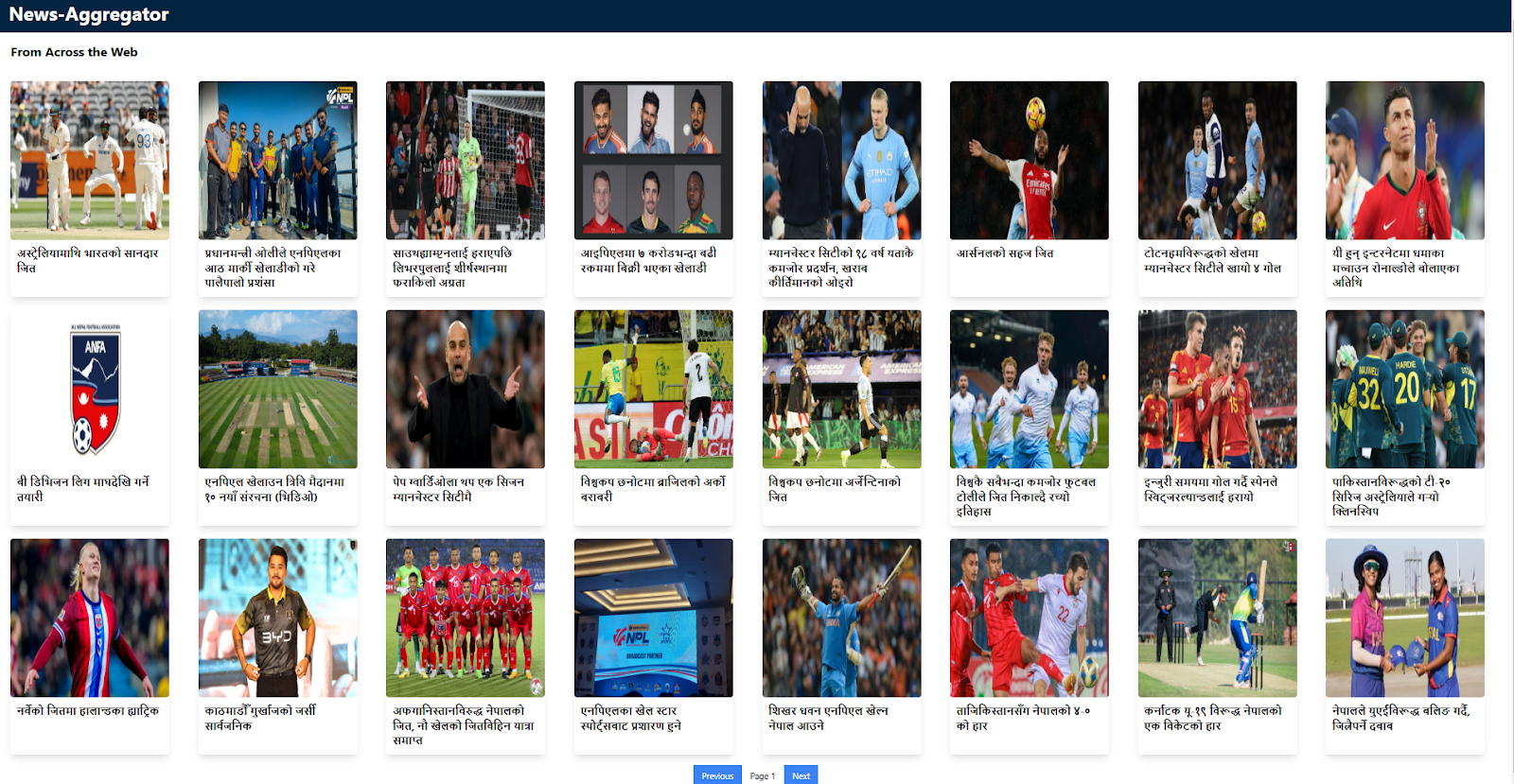
When the user clicks on any news, they will be redirected to the source of the news.
Prerequisites
The readers should have basic knowledge of Python, Object Oriented Programming, Django, RestAPI, Web Scraping, and React.We will be using the following tools and technologies:
- Scrapy (for scraping websites)
- PostgreSQL (for storing scraped data)
- Django with Django Rest Framework (for building APIs)
- React (frontend development)
Overviews of the Technologies Used
Django
Django is an open-source, high-level Python web framework that promotes rapid development and clean, pragmatic design.It comes with built-in ORM, admin interface, authentication, and more.
Django Rest Framework (DRF) is a powerful toolkit for building Web APIs using Django. It is used for creating RESTful APIs for mobile and web applications and integrates seamlessly with Django.
PostgreSQL
PostgreSQL is an open-source relational database management system (RDBMS) known for its scalability, extensibility, and compliance with SQL standards.
Scrapy
Scrapy is a powerful, open-source Python framework designed for extracting data from websites (web scraping), processing it as required, and storing it in a structured format. It is widely used for building web crawlers and automating data collection tasks. Scrapy is known for its speed, simplicity, and scalability.
React
React is a JavaScript library for building user interfaces, particularly single-page applications.
Project Overview
We will be building a web application that will extract title, news link, and image link, from each recent news article available on our target news websites, using Scrapy. Then we will store the news in our database which will be a PostgreSQL database. After that we will build an API which will list the stored news data, using Django Rest Framework. Finally we will consume the API in our React application.The blog is divided into 3 parts. In this part we will build the API to list all news items from our database. Then in the next part we will use Scrapy to gather and store data from our target websites. The third part will be about building a React application to show the data stored in our database.
We will structure our project in the following way:
news-aggregator/
├── api/
├── config/
├── frontend/
└── scraper/
Setting up the Backend
Let’s start with setting up the backend. Windows Operating System with Visual Studio Code as the code editor is recommended, but you can use other OS and code editors too.Start by creating an empty folder. I have created an empty folder: news-aggregator. We will call this folder root directory from here on. Create and activate a virtual environment inside the root directory, then install django:
pip install django
After installation is finished, create a Django project. Run the command:
django-admin startproject config .
Don’t forget to include the period . at the end which installs the code in our
current directory. If you do not include the period, Django will create an additional
directory by default.
I have named my project config because it just holds a collection of configuration files for Django.
Now we will create a Django app. I will name my app: api. To create a Django app run the command:
python manage.py startapp api
This will create a folder called api in the current directory. The folder itself is a django app. It contains a folder called migrations, and the files: admin.py, apps.py, models.py, views.py, among others.
Register your app in settings.py file, located in the config directory, by adding it inside the INSTALLED_APPS list.
news-aggregator/config/settings.py
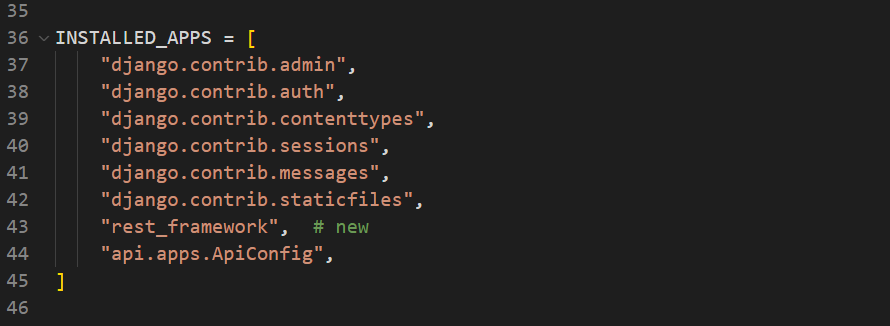
Also change the timezone in the TIME_ZONE settings to Asia/Kathmandu.
news-aggregator/config/settings.py

Then, set up PostgreSQL. You can download PostgreSQL from: https://www.postgresql.org/download/
During the installation, select all the components: PostgreSQL Server, pgAdmin4, Stack Builder and Command Line Tools to be installed.
Set your password for the superuser (postgres). Also specify the port to run the Postgres server. I set it to 5432.
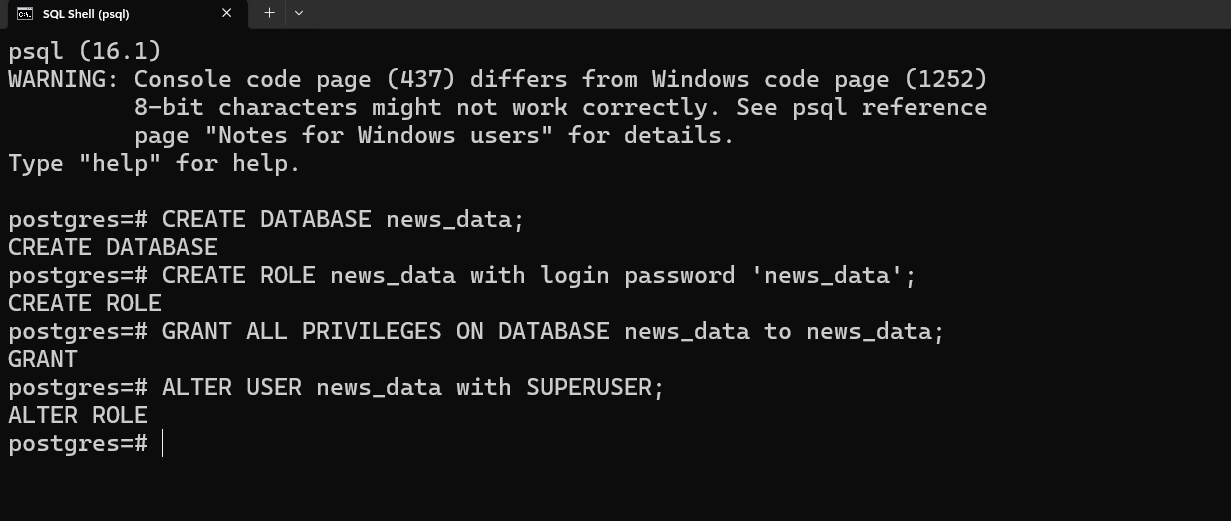
After that, create a database and a user to access that database. You can do so through the Psql shell. Search for ‘psql’ in the search bar and open SQL Shell. Type the commands to create a database, and a database user. I set my database name, username and password to news_data.
Now let’s connect the database to our Django app.
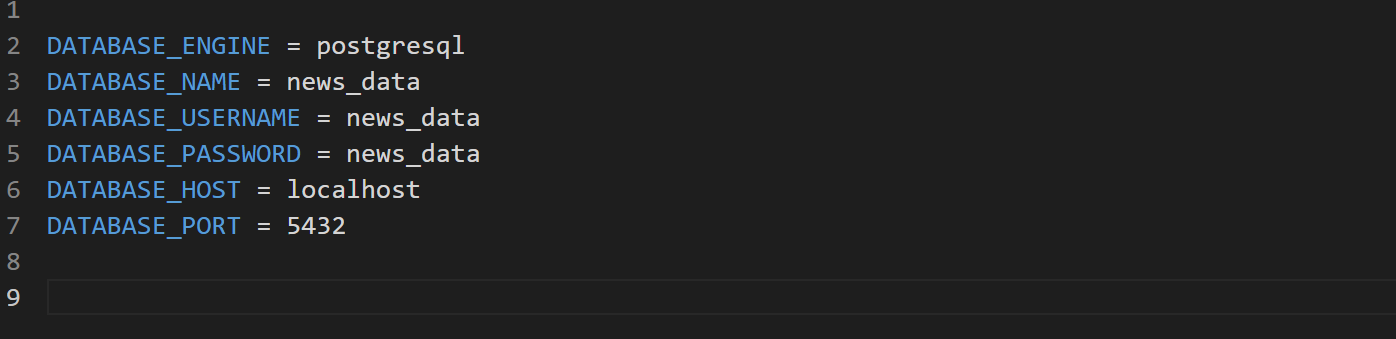
Create a .env file inside the root directory and store the database configuration in it. Mine looks like this:
news-aggregator/.env
Then, install python-dotenv to load the .env file.
pip install python-dotenv
In the settings.py inside the config directory file import os and load_dotenv, then initialise load_dotenv.
news-aggregator/config/settings.py

After that add the database settings.
news-aggregator/config/settings.py

We will need the module psycopg2 to interact with Postgres, install it by running:
pip install psycopg2
Now run migrations with:
python manage.py migrate
We will test if everything up to this point is working by starting the server. To start the server run:
python manage.py runserver

It will start a development server at your local address. You can get the address of the server running from the terminal, after the line:
Starting development server at…
In my case it is: http://127.0.0.1:8000/
You should get a page like this when you go to the address.
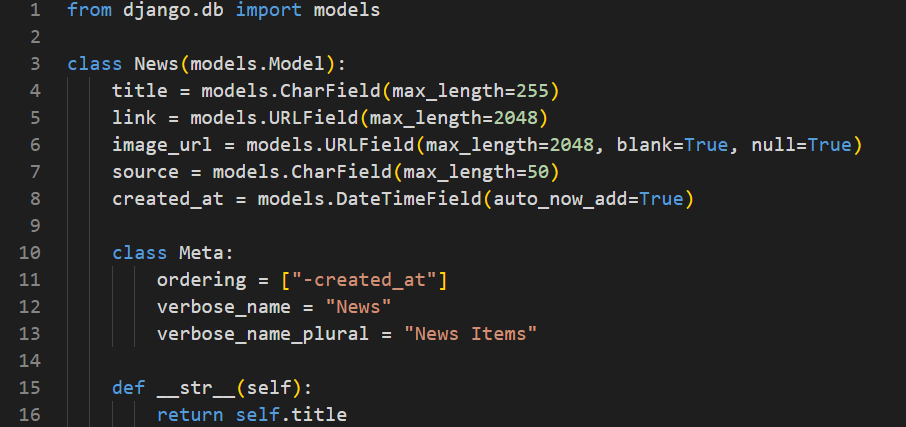
Now lets create a table to store the news items. Open the models.py file inside the api directory.
We will create a model called News, which will have the following fields:
title – A character field with max length of 255 characters,
link – A URL field with max length of 2048 characters,
image_url – A URL field with max length of 2048 characters. It will be an optional field as specified by blank = True, and null = True,
source – A character field with max length 50. The source of the news items will be stored in this field,
created_at – A datetime field whose value will be the timestamp on which a news item is added
news-aggregator/api/models.py
The field ordering inside the Meta class specifies the default ordering of the news items. -created_at specifies the news items to be ordered in descending order based on their created_at field’s value. We do this so that the latest news will be on the first page.
The field: verbose_name provides a human-readable singular name for the model (e.g News) and the field: verbose_name_plural provides a human-readable plural name for the model (e.g News instead of Newss).
The function at the bottom: __str__ specifies how objects of this model are represented as strings. When we print an instance of the News model (e.g., in the Django admin, shell, or logs), it will display the value of the title field instead of something like
Now run the migrations to create the table. Go to the terminal and run migrations with the command:
python manage.py makemigrations api
After the process finishes run:
python manage.py migrate
This will create the table api_news in our database. Django adds a prefix, name of the app_ in the name of the table it creates. In our case the name of the app is api hence the table is named: api_news
In order to view the table from the Django admin panel, we have to register it. To do so, go to admin.py inside the api directory, import the model News, and register it there.
news-aggregator/api/admin.py

Now create a superuser. Superusers can access the admin panel. In order to create superuser, in your terminal, run:
python manage.py createsuperuser
in the terminal. You will be prompted to enter username, email and password.
Set your username and password. Email is optional so you can skip it. You will need the username and password you have set here to login to the admin panel.
After creating superuser, run the server with:
python manage.py runserver
You can open the URL followed by /admin in the browser and the admin panel will open.

Login to the admin panel with the superuser credentials. Verify that the code up to now is working by adding a news item.
Since we will be using React as the frontend we will need an API to fetch all news items. For that we will use Django Rest Framework (DRF).
To install DRF run:
pip install djangorestframework
After the installation is done, register DRF to your project. To do so add the rest framework to the list of INSTALLED_APPS in the settings.py.
news-aggregator/config/settings.py
Make sure that rest_framework is before api.apps.ApiConfig
Now we will need a serializer. A serializer translates data received from the database into a format that is easy to consume over the internet, typically JSON.
Create a file named serializers.py inside the api directory, and create a serializer called NewsSerializer.
news-aggregator/api/serializers.py
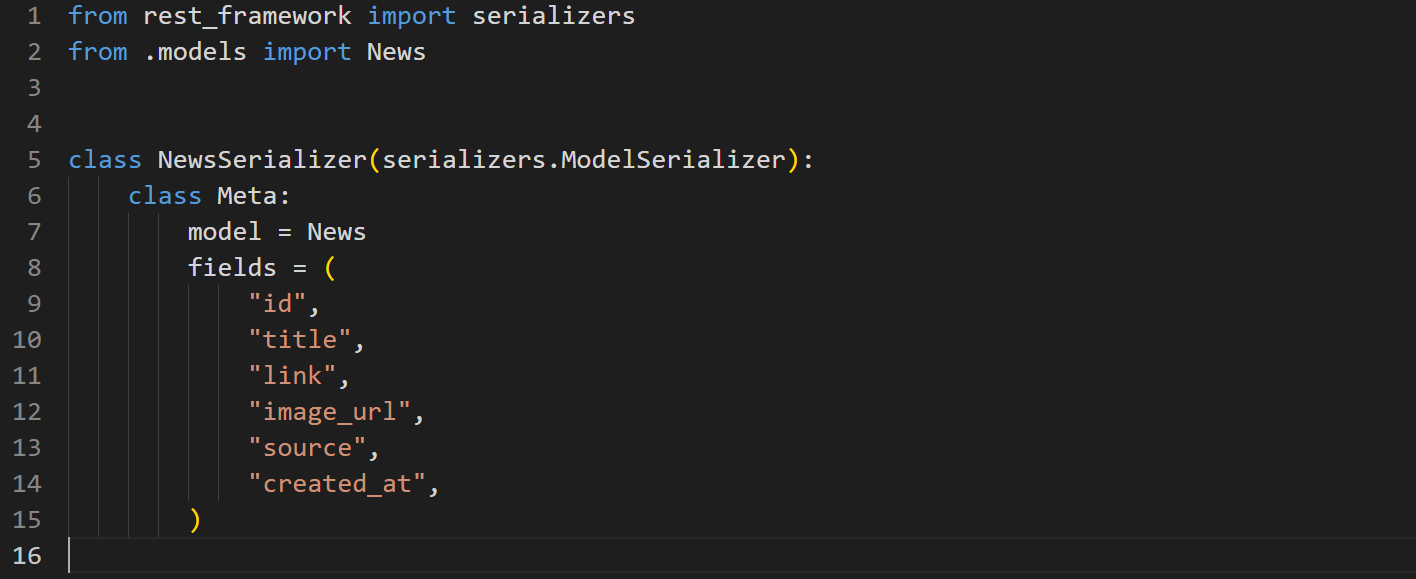
Here we defined a serializer. Inside the Meta class of the serializer, we specify which model to use and which fields of the model to expose.
Notice the id field here, in our News model we didn’t specify an id field, but we are including it here. By default, if you do not specify a primary key in your model, Django creates an id field whose value automatically increments with each new record.
We will need the id of each news item in our frontend so we have added it to the tuple of the fields to expose.
Now that we have created a serializer, let’s create a view. View handles requests and returns appropriate responses.
Go to views.py inside the api directory. The views.py is already created when starting a django app. Inside the views.py, create a view called ListNews
news-aggregator/api/views.py
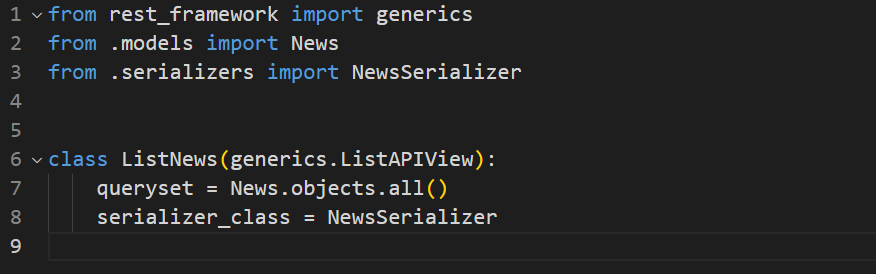
Here we created a view called ListNews which runs the query to fetch all news from the News table. And we defined the NewsSerializer to be used to serialise the data.
Now we have reached the final step in creating our API using DRF. Create a urls.py file inside the api directory, and register the ListNews view.
news-aggregator/api/urls.py
Then we tell Django to return the ListNews view when the url is the base url followed by /api/ i.e, http://127.0.0.1:8000/api/
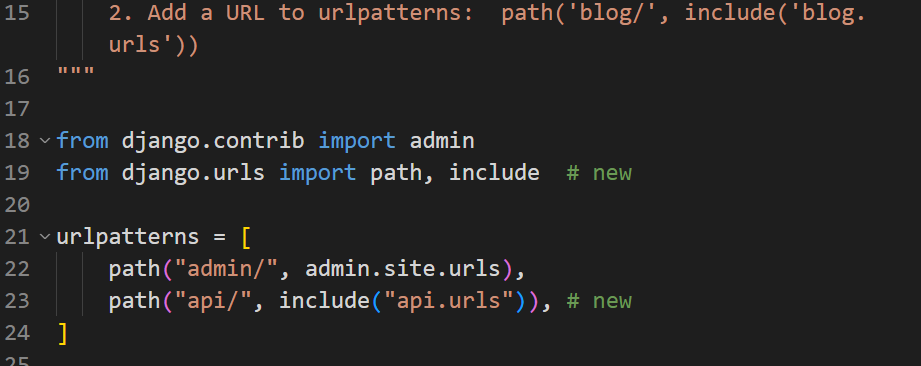
Go to urls.py inside the config directory, and register the URL of the API
news-aggregator/config/urls.py
After that, start the server, and open the base URL followed by /api (http://127.0.0.1:8000/api/) in your browser.
You should get a page similar to this:
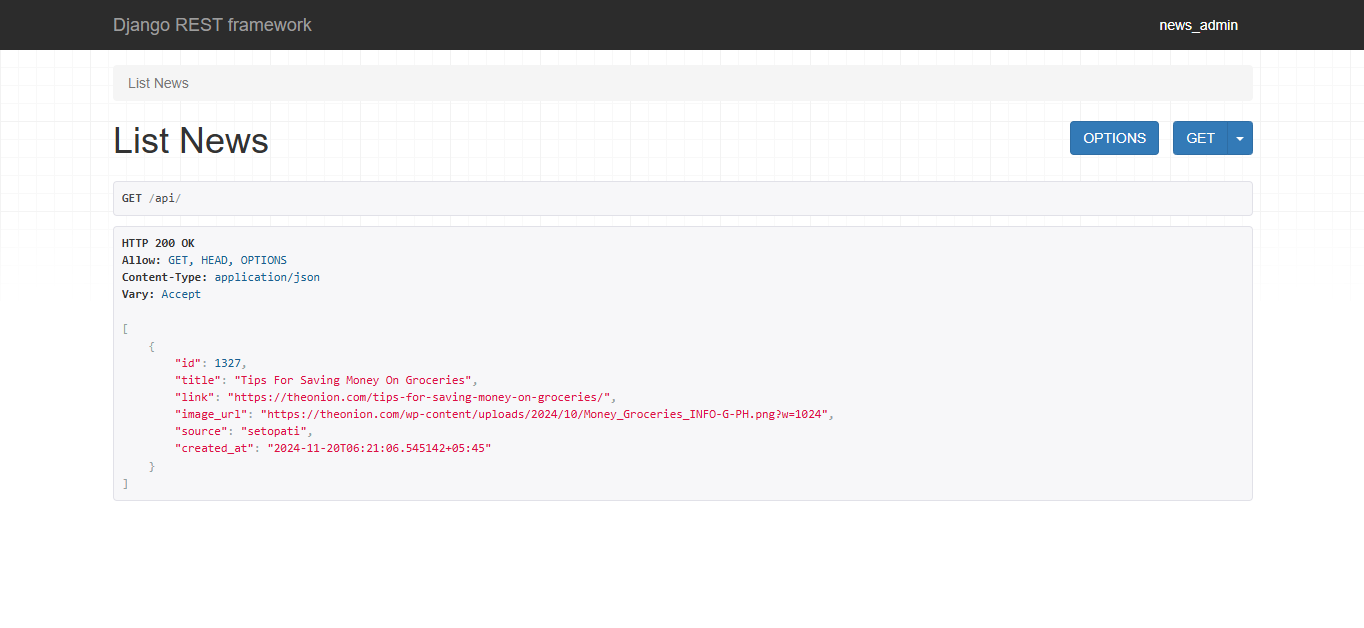
Here you can see that the news from our database are listed, if you have added a sample news item from the admin panel.
In the frontend, we don’t want to display news items from our database all at once, instead we want to display a specific number of news in the first page then we want the rest of the news in other pages. For that we can use pagination provided by DRF. To use the pagination go to settings.py and specify the DRF pagination settings:
news-aggregator/config/settings.py

Here we are defining the pagination to be used: Page Number Pagination. And the number of items a page will have: 24 in this case.
Save your changes and reload the API, you will see that the response has count, next, previous along with results. Count specifies the total number of records in the database, next specifies the URL to the next page, previous specifies the URL to the previous page, and results contains a list of news objects.
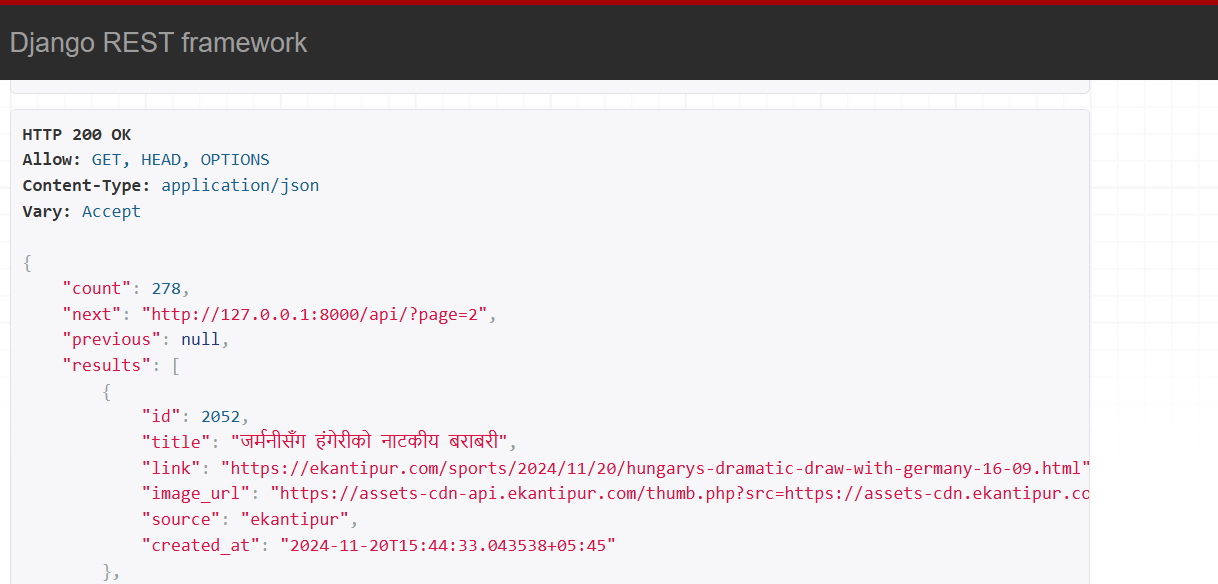
With the API set up this way, we will just follow the next URL until it becomes null, to get all the news items from our database.
This concludes the first part of our blog. In this part we created an API to list all the news items available in our database using Django and Django Rest Framework. In the next part we will be using Scrapy to gather news items from different websites and store them in our database.